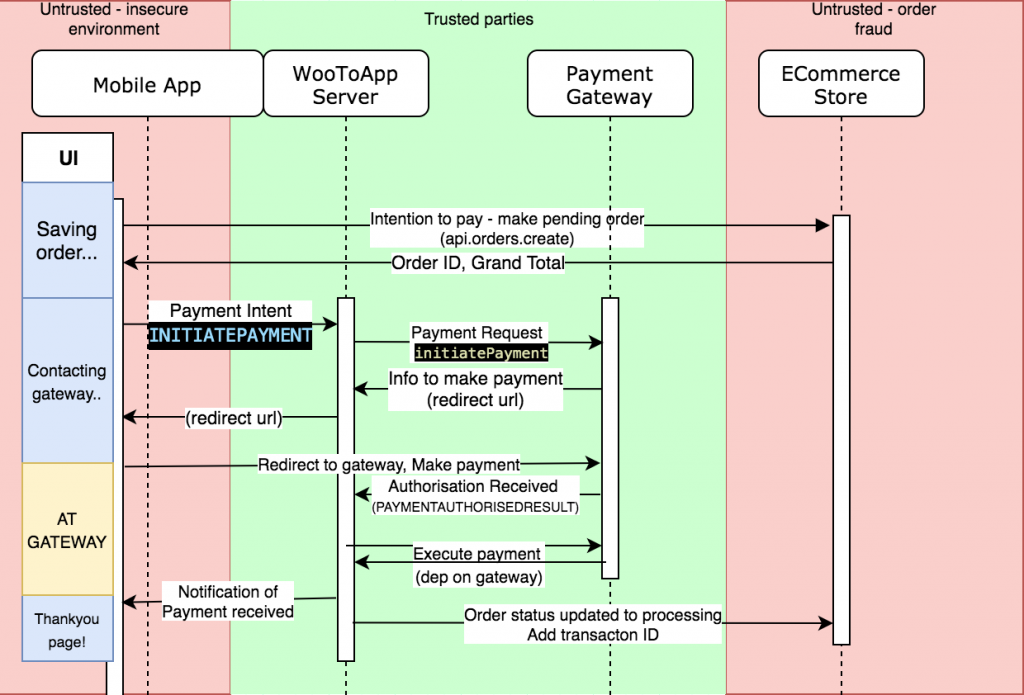
These are notes and additions from working through this youtube video. In the video and in the notes below, the AWS CLI is used to configure Lambdas, a Dynamo DB and an API Gateway.
Setting up an IAM user
Visit the IAM Console and create a ‘Programmatic Access’ user.
Add the user to ‘Administrator’ group.
Install the AWS CLI tools.
brew install awscli
Configure AWS CLI tools.
aws configure
Paste in the Access Key ID and the Secret Access Key. Leave region name and output format as defaults.
Dynamo DB – Create a table
aws dynamodb create-table --table-name ToDoList \
--attribute-definitions AttributeName=Id,AttributeType=S \
AttributeName=Task,AttributeType=S \
--key-schema AttributeName=Id,KeyType=HASH \
AttributeName=Task,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5
We’ve created a table with columns Id (S=String) and Task (S=String).
We’ll need the TableArn later, so use this JQ command to store the TableArn in an environment variable.
TABLEARN=$(aws dynamodb describe-table --table-name ToDoList | jq '.Table .TableArn')
Create role and policy
The role is a fairly standard template, and is just a bare role with lambda access.
Save the following to lambda_role.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": ["lambda.amazonaws.com"]
},
"Action": "sts:AssumeRole"
}
]
}
Create the role on AWS:
aws iam create-role --role-name lambda-role --assume-role-policy-document file://lambda_role.json
The policy adds put and scan permissions to the role.
Create policy.json and add the following. Replace the Resource value with the output from echo $TABLEARN (that we saved above).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["dynamodb:PutItem", "dynamodb:Scan"],
"Resource": "replace me---->arn:aws:dynamodb:us-east-1:478724445133:table/ToDoList"
}
]
}
Attach the policy to the role.
aws iam put-role-policy --role-name lambda-role --policy-name dynamodb-access --policy-document file://policy.json
We’ll save the role ARN for use later (we need to assign it to the lambda scripts later on).
ROLE_ARN=$(aws iam list-roles | jq '.Roles[] | select(.RoleName=="lambda-role") | .Arn' -r) && echo $ROLE_ARN
Create the node.js scripts & turn them into Lambdas.
First up is the file that fetches our to-dos from DynamoDB. It uses a full scan, and there’s no filtering or paging.
Run code get.js and drop in this code to scan the table:
const AWS = require("aws-sdk");
const documentClient = new AWS.DynamoDB.DocumentClient();
exports.getAllTasks = (event, context, callback) => {
const params = {
TableName: process.env.TABLE_NAME,
};
documentClient.scan(params, (err, data) => {
if (err) {
callback(err, null);
} else {
callback(null, data.Items);
}
});
};
zip it up with zip get.zip get.js
We’ll push up get.zip and turn it into a lambda:
aws lambda create-function --function-name get-all-tasks --zip-file fileb://get.zip --runtime nodejs8.10 --role "$ROLE_ARN" --handler get.getAllTasks --environment Variables={TABLE_NAME=ToDoList}
Same goes for post.js. code post.js, paste this code in. This takes the task supplied and pushed it to the TableName table in DynamoDB. TableName will be populated by an environment variable later when we use these lambdas.
const AWS = require("aws-sdk");
const uuid = require("uuid");
const documentClient = new AWS.DynamoDB.DocumentClient();
exports.addTask = (event, context, callback) => {
const params = {
Item: {
Id: uuid.v1(),
Task: event.task,
},
TableName: process.env.TABLE_NAME,
};
documentClient.put(params, (err, data) => {
if (err) {
callback(err, null);
} else {
callback(null, data.Items);
}
});
};
Zip it up: zip post.zip post.js
Save as a lambda function:
aws lambda create-function --function-name add-task --zip-file fileb://post.zip --runtime nodejs8.10 --role "$ROLE_ARN" --handler post.addTask --environment Variables={TABLE_NAME=ToDoList}
Creating the API
Creating the API involves a ton of steps. I’ve made heavy use of environment variables below to save the chopping/changing and leave less room for errors.
- Creating the API Gateway
- Creating the route (resource)
- Adding methods to the route (GET & POST)
- Adding responses to the methods
- Adding integrations (connecting up the lambdas)
- Adding integration responses
- Deploy to a stage
Create the API:
aws apigateway create-rest-api --name 'To Do List'
Capture the Rest API ID (into APIID) for later use (we will need to use this *a lot*. Capture the ROOT ID as well (the ID of the resource that serves /
APIID=$(aws apigateway get-rest-apis | jq '.items[] | select(.name=="To Do List") | .id' -r) && echo $APIID
ROOTID=$(aws apigateway get-resources --rest-api-id $APIID | jq '.items[] | select(.path=="/") | .id' -r)
Create the /tasks resource/route. (And on the second line, capture it in an environment var)
aws apigateway create-resource --rest-api-id $APIID --parent-id $ROOTID --path "tasks"
TASKSID=$(aws apigateway get-resources --rest-api-id $APIID | jq '.items[] | select(.path=="/tasks") | .id' -r)
Add GET and POST methods to the new /tasks endpoint
aws apigateway put-method --rest-api-id $APIID --resource-id $TASKSID --http-method GET --authorization-type NONE
aws apigateway put-method --rest-api-id $APIID --resource-id $TASKSID --http-method POST --authorization-type NONE
Add a 200 response handler to the 2 new methods.
aws apigateway put-method-response --rest-api-id $APIID --resource-id $TASKSID --http-method GET --status-code 200
aws apigateway put-method-response --rest-api-id $APIID --resource-id $TASKSID --http-method POST --status-code 200
Create the integrations: head over to the AWS Management Console and manually wire up the Lambda to the API Gateway (GET/POST)
Connecting the lambda to the API Gateway method is an integration. Add an integration response of 200 for the 2 integrations.
aws apigateway put-integration-response --rest-api-id $APIID --resource-id $TASKSID --http-method GET --status-code 200 --selection-pattern ""
aws apigateway put-integration-response --rest-api-id $APIID --resource-id $TASKSID --http-method POST --status-code 200 --selection-pattern ""
Now we’re ready to deploy the API. Pick a stage name (such as dev) and deploy the API to the stage.
aws apigateway create-deployment --rest-api-id $APIID --stage-name dev
Now you can request the todos from the API, and post new todos.
Note ‘dev’ below is the stage name. Save the endpoint address:
ENDPOINT=https://$APIID.execute-api.us-east-1.amazonaws.com/dev/tasks
Save a new item to the endpoint:
curl -X POST -d '{"task": "Eat"}' $ENDPOINT
Request all items from the endpoint (and use jq to pretty print):
curl -X GET $ENDPOINT -s | jq